Indexación y asociación
Introducción
Un índice es un tipo de lista que contiene elementos que nos llevan de manera directa a la ubicación de otros elementos.
Cada vez que ejecutamos una consulta, la base de datos busca todas las filas de su tabla para encontrar las que coincidan con la solicitud. A medida que crecen las tablas de la base de datos, es necesario inspeccionar un número mayor de filas que a su vez, disminuye el rendimiento general de la base de datos y, respectivamente, de la aplicación.
Los índices de MySQL resuelven este problema tomando datos de una columna en su tabla y almacenándolos alfabéticamente en una ubicación separada llamada índice.
En bases de datos, un índice es una estructura de datos formada por dos campos:
Clave de búsqueda: es una atributo (o varios) y es lo que se usa para buscar por el índice.
Puntero: es la referencia a la ubicación del disco donde se encuentra el registro de la base de datos.
Los índices en bases de datos nos permiten reducir el tiempo de búsqueda y el acceso a los datos.
Los índices mantienen una referencia a la posición exacta donde se encuentra un dato.
Existen diferentes técnicas de indexación y asociación pero ninguna es mejor que la otra, pues todo depende del tipo de aplicación que se esté utilizando. Cada técnica se puede analizar atendiendo a los siguientes criterios:
Tipos de acceso: Se pueden referir a búsquedas de registros con un valor concreto o registros con valores dentro de un rango.
Tiempo de acceso.
Tiempo de inserción: Indica el tiempo necesario para insertar un valor, incluyendo el necesario para actualizar la estructura de índices.
Tiempo de borrado.
Espacio adicional requerido por la tabla de índices.
Tipos de índices
Índices ordenados
Almacenan datos ordenados en función del valor de la clave de búsqueda.
Se pueden clasificar de dos formas:
Según el campo sobre el que se realiza el índice:
Primario: si el índice se realiza sobre la clave de ordenación en disco (PK sin duplicados).
Secundario: si el índice se realiza sobre otro campo (con duplicados o no) que no es clave de ordenación.
Según la cantidad de información almacenada:
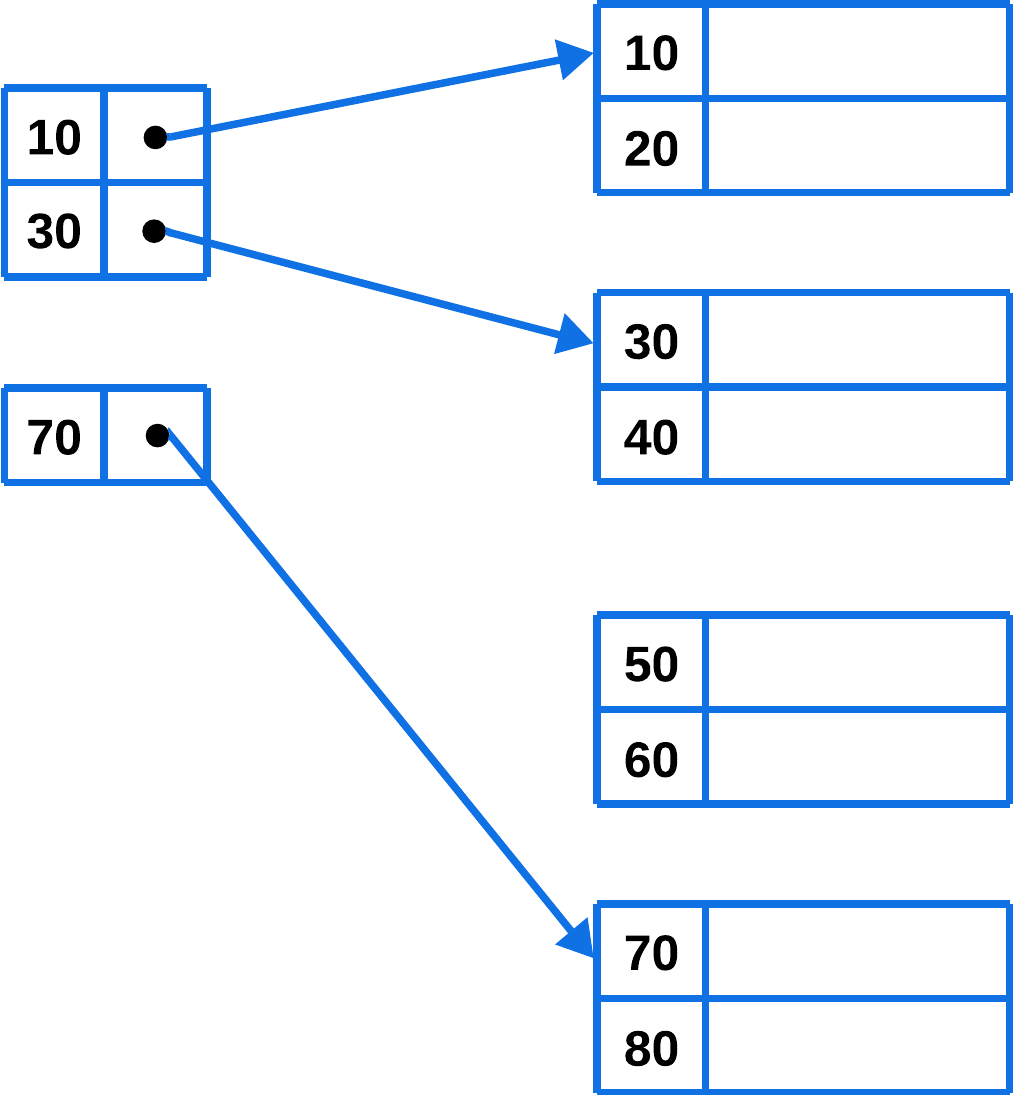
Denso: cuando en la tabla de índices aparece un valor de índice por cada valor posible de la clave de búsqueda.
Ventaja: La velocidad de acceso a los datos es mayor.
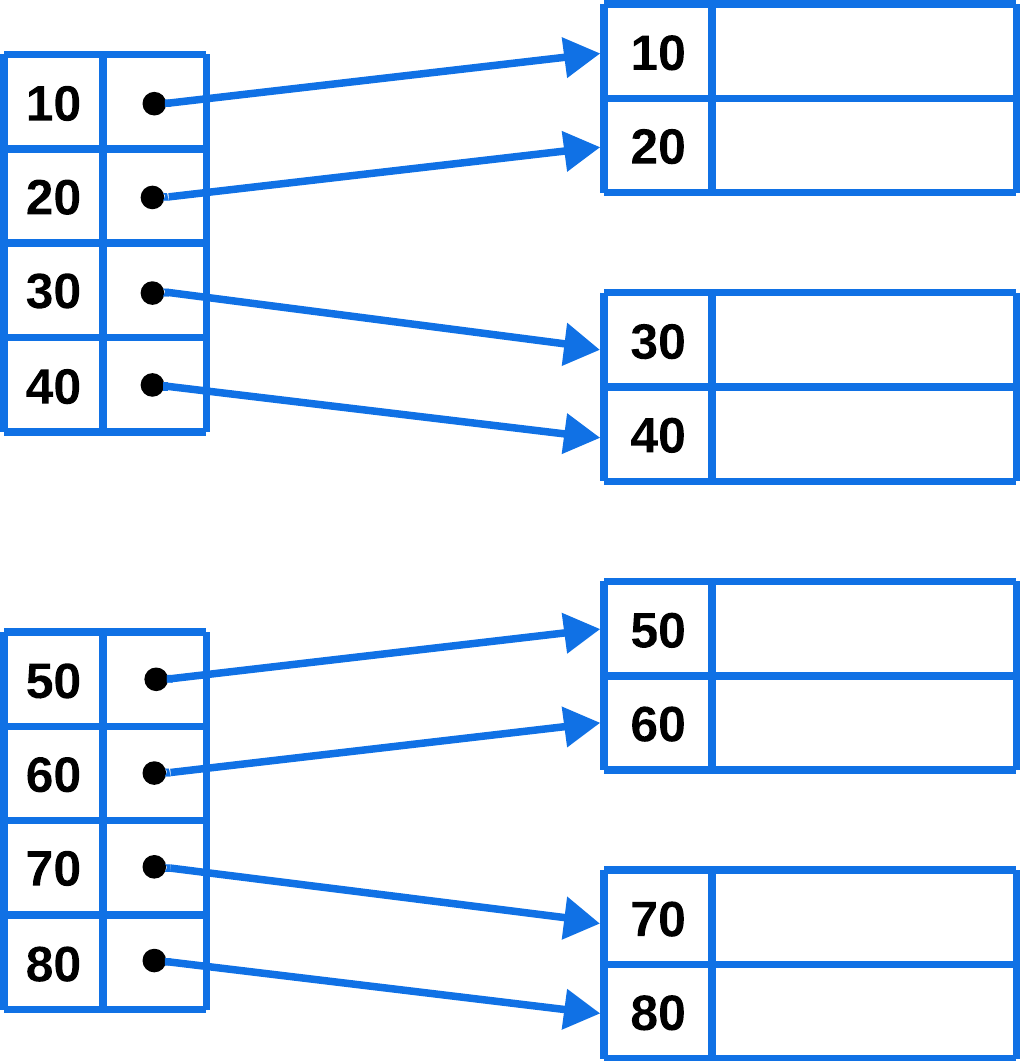
Disperso: solo se crea una entrada de índice para ciertos valores, siendo necesario recorrer un rango de memoria, completo en el peor caso.
Ventajas: Requieren menos espacio de almacenamiento y un coste de mantenimiento menor derivado de inserciones y borrados.
Índices asociados
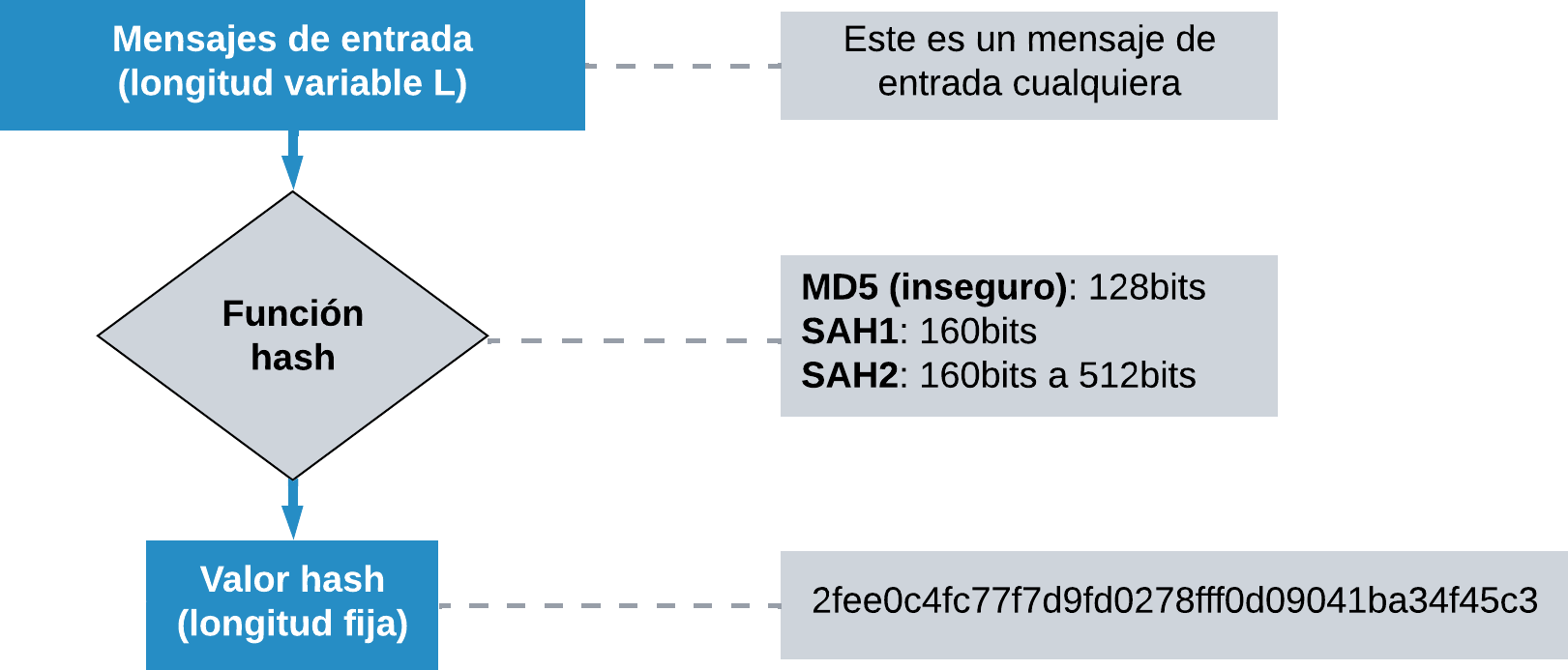
Función hash
Una función hash es un algoritmo matemático que transforma un dato en otro unidireccionalmente.
Las mismas entradas siempre devuelven las mismas salidas, ya que no es un proceso aleatorio.
Es irreversible.
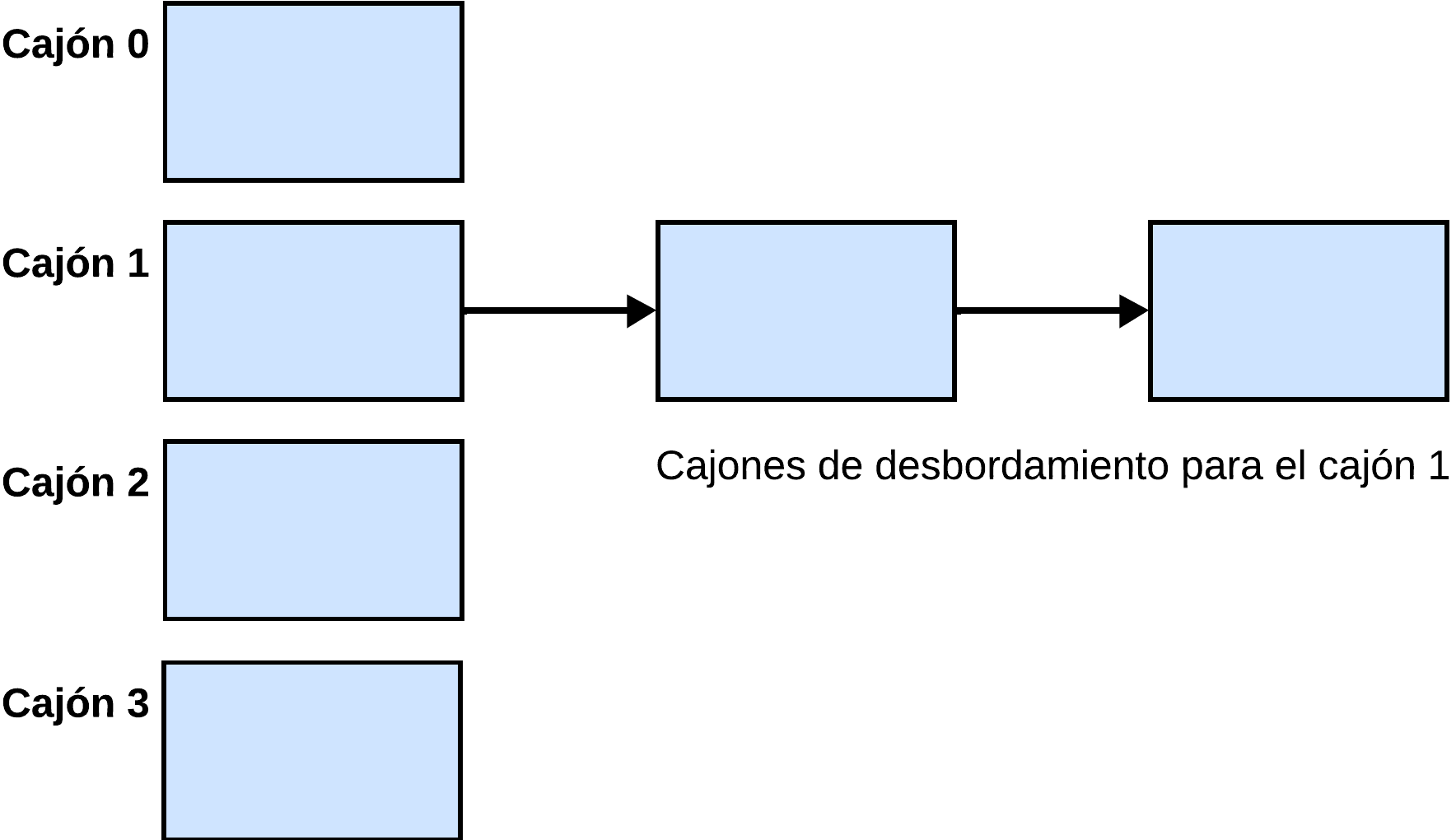
Los registros se almacenan uniformemente a lo largo de cajones utilizando una función de asociación (hash sobre uno o varios atributos). Podríamos decir que es como una lista de listas.
No hay ningún tipo de ordenación en base al valor, como si ocurre en los índices ordenados.
Definiciones:
Cajón: unidad de almacenamiento para uno o más registros.
Función de asociación: es una función que, dado un valor de clave, indica el cajón en el que está.
Almacenamiento de índices
Los índices pueden estar almacenados en RAM o en disco, todo dependerá del uso que le demos a esos índices.
Hay SGBD que son capaces de mover los índices de uno a otro sitio dependiendo de su uso, así que si un índice es muy utilizado, lo moverá a RAM, y por el contrario, si no se usa desde hace tiempo, lo devolverá a disco.
En memoria:
Acceso rápido a los datos por cercanía.
Espacio de almacenamiento limitado y más caro.
En disco:
Acceso más lento a los datos.
Espacio de almacenamiento "ilimitado" y más barato.
Índices multinivel
Cuando nuestro índice es excesivamente grande, queremos que al menos una parte de este se encuentre en memoria para agilizar el acceso.
Los índices multinivel buscan reducir el espacio que pueden ocupar los índices grandes y así poder tener una parte del índice en memoria (normalmente índice disperso) y el resto en disco (disperso, denso o asociativo).
Al utilizar dos niveles de indexación y manteniendo el índice más externo en la memoria principal mejora el tiempo de búsqueda. Si el índice externo crece demasiado y no cabe en la memoria principal, se podría repetir el proceso, volviendo a crear otro índice más externo.
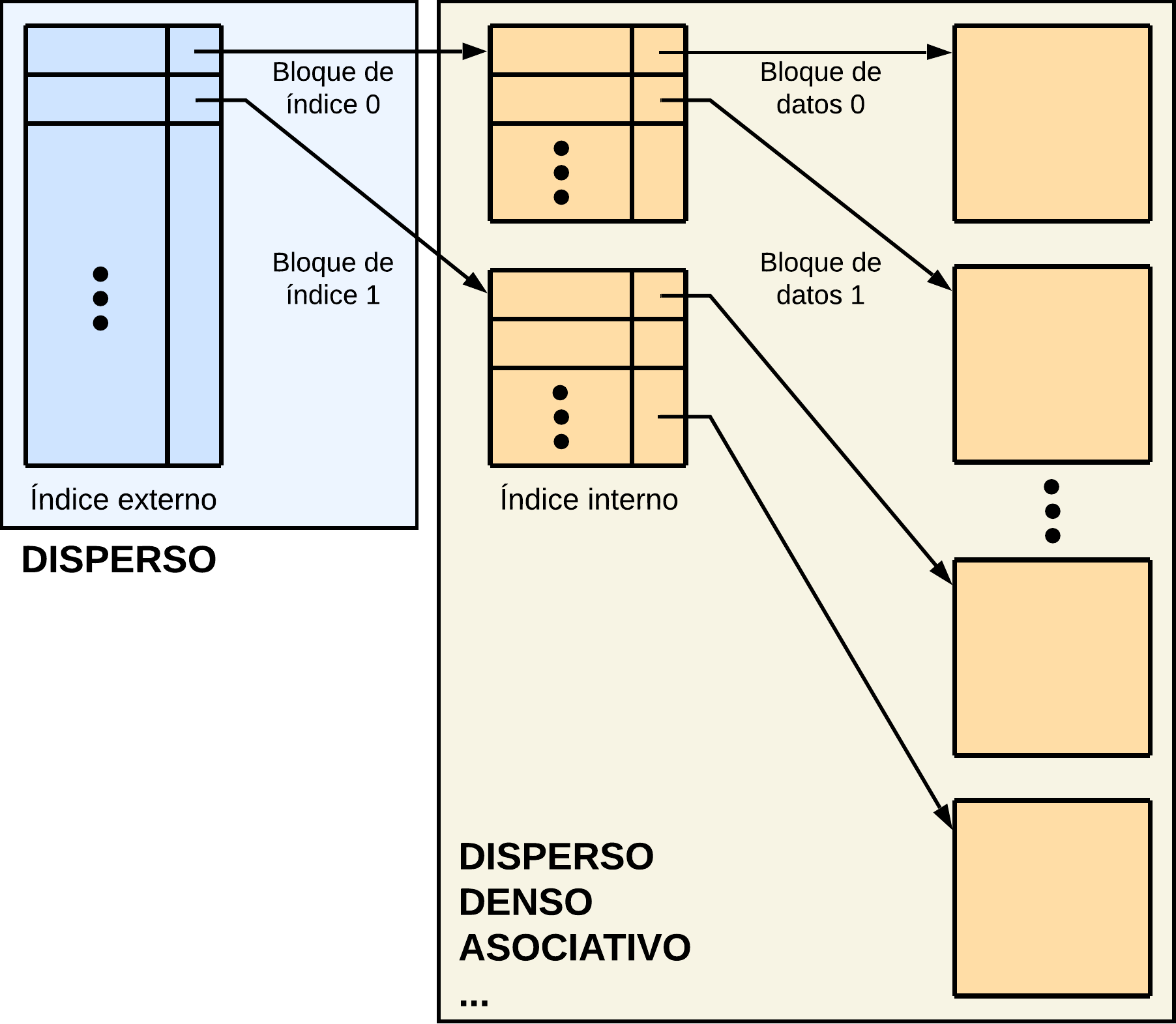
El proceso de búsqueda se divide en dos:
Índice más externo → búsqueda binaria.
Índice interno → búsqueda secuencial.
Actualización del índice
Independientemente del tipo de índice que estemos utilizando, estos deben actualizarse siempre que se inserte o borre un registro.
La actualización de los índices impone un tiempo adicional en la modificación de los datos de la base de datos.
Borrado
Índice denso: el borrado de la clave de búsqueda es similar al borrado de un registro.
Índice disperso:
Si una entrada para la clave de búsqueda existe en el índice, se borra reemplazando la entrada en el índice con la siguiente clave de búsqueda (en orden).
Si la siguiente clave de búsqueda ya tiene una entrada, se borra sin más.
Inserción
En primer lugar se realiza una búsqueda usando el valor de clave de búsqueda del registro a insertar. Las tareas a realizar dependen del tipo de índice:
Índices densos: el valor de la clave de búsqueda se inserta en el índice.
Índices dispersos: se crea una entrada en el bloque correspondiente. Si hubiese que crear un bloque nuevo, el primer valor de la clave (en orden) que aparezca en el nuevo bloque es el valor a insertar en el índice.